[JAVA] Exception
Seongje kim, 06 February 2020
이번 포스트 주제는 Java의 예외 처리에 대한 내용입니다. 예외 처리는 프로그램 코드 작성 시 가장 신경써야 할 요소이며 보다 안전하고 유연한 프로그래밍을 위해 필수적으로 활용되어야 한다고 생각합니다. 따라서 이번 포스트를 통해 예외 처리에 대한 중요성를 이해하고 올바르게 적용하는 것이 목표입니다.
예외 (Exception)
우선 ‘예외(Exception)’ 는 ‘오류(Error)’ 와 구분되는 개념이다.
-
오류 : 시스템의 비정상적 상황에 발생한다. 이는 시스템 레벨에서 발생하는 문제이기 때문에 비교적 심각한 수준이다. 따라서 개발자가 코드 작성 시 미리 예측할 수 없는 문제이며, 애플리케이션 레벨에서 이에 대한 처리가 필요하지 않다.
-
예외 : 오류와 달리 애플리케이션 레벨에서 개발자가 구현한 로직에서 발생하며 프로그램의 오작동을 막는다. 따라서 개발자의 입장에서 예외가 발생할 수 있는 상황을 미리 예측하여 처리할 수 있다. 그러므로 개발자는 코드 작성시 특정 상황에 따른 예외들을 구분하고, 이들을 어떻게 처리를 해야 하는지 고려하여 적절히 적용하는 것이 필요하다.
결과적으로 우리가 해결해야 할 것은 바로 ‘예외’ 이다.
예외 클래스 (Exception Class)
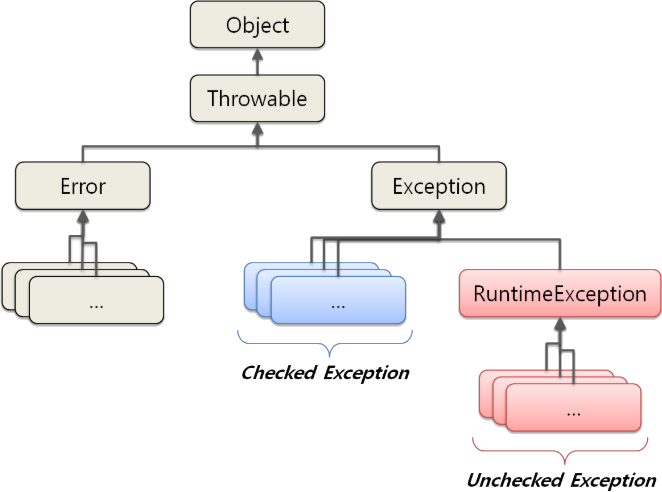
위 그림은 예외 클래스의 구조이다. Trowable 클래스를 상속받는 클래스는 Error 와 Exception 클래스로 나뉜다. 개발자는 애플리케이션 레벨에서 발생 가능한 문제를 이 Exception 클래스를 이용하여 처리할 수 있다. 예외가 발생할 수 있는 상황이 다양한 만큼 Exception 클래스는 수많은 자식 클래스를 가진다.
Exception 클래스는 다시 RuntimeException 클래스와 이외의 클래스들로 나뉜다. RuntimeException 클래스는 Exception 클래스를 Checked Exception 과 Unchecked Exception 으로 나누는 기준이 된다. 즉, RuntimeException 클래스와 그 자식 클래스들은 Unchecked Exception, 이들을 제외한 Exception 클래스의 모든 자식 클래스들은 Checked Exception 이다.
Checked vs Unchecked(Runtime)
Exception 을 Checked 와 Unchecked 로 구분하는 기준은 ‘반드시 처리가 필요한가’ 이다.
Unchecked Exception 은 말 그대로 확인되지 않은 예외 즉, 컴파일 단계에서 확인되지 않고 실행 단계에서 발생하는 예외이다. 주로 개발자의 부주의로 발생하는 경우가 대부분이며, 컴파일 시 문제가 되지 않기 때문에 굳이 명시적인 처리가 필요하지 않다. 즉, 개발자는 실행 단계에서 예외가 발생하지 않도록 코드 작성 시 주의를 기울이는 것이 중요하다. 대표적으로 IndexOutOfBound, NullPointer Exception 등이 있다.
Checked Exception 는 이미 예측 가능한 예외들로써 해당 예외가 발생할 수 있는 로직에는 반드시 명시적인 처리를 해야 한다. 이 예외들은 컴파일 단계에서 명확한 확인이 가능하기 때문에 만일 예외를 처리하지 않는다면 컴파일 시 오류가 발생한다. 대표적으로 I/O, SQL Exception 등이 있다.
또한 두 예외는 ‘예외 발생 시 트랜잭션(Transaction)의 Roll-back 여부’ 에 대해서도 차이가 있다. ‘트랜잭션’ 이란 하나의 작업 단위를 뜻한다. 이 트랜잭션을 처리하는 과정에서 예외가 발생했을 때, 작업의 모든 단계를 취소하고 작업을 초기화하는 것이 바로 ‘Roll-back’ 이다. 기본적으로 Checked Exception 은 예외가 발생하면 트랜잭션을 Roll-back 하지 않고 예외를 던져준다. 하지만 Unchecked Exception 은 예외 발생 시 트랜잭션을 Roll-back 한다는 점에서 차이가 있다.
추가적으로 트랜잭션을 어떻게 묶어놓는가 즉, 전파 방식(Propagation Behavior)에 따라 Checked Exception 과 Unchecked Exception 의 차이가 미치는 영향을 알아야 한다. 결과적으로 트랜잭션의 전파 방식과 예외에 따라 작업이 Roll-back 되는 범위가 달라지기 때문에 개발자가 이를 인지하지 못한다면 실행 결과가 맞지 않거나 예상치 못한 예외가 발생할 수 있다. 그러므로 이를 인지하고 트랜잭션을 적용시킬 때, 전파 방식 및 Roll-back 규칙을 적절히 사용하면 더욱 효율적이고 안전한 애플리케이션을 구현할 수 있을 것이다.
| 구분 | Checked Exception | UnChecked Exception | ||
|---|---|---|---|---|
| 예외 처리 여부 | 반드시 예외 처리가 필요 | 명시적인 예외 처리를 강제하지 않음 | ||
| 확인 시점 | 컴파일 단계 | 실행 단계 | ||
| 트랜잭션 처리 | Roll-back : O | Roll-back : X | ||
| 대표 예시 | IOException, SQLException | NullPointerException, IllegalArgumentException, IndexOutOfBoundException, SystemException |
예외 처리 방법
예외 처리는 기본적으로 ‘try-catch’ 구문을 통해 수행된다. try 문에서 예외 발생하면 즉시 중단되고, catch 문을 통해 해당 예외 맞는 처리를 수행한다.
try {
// ... 예외 발생시, 즉시 중단되고 해당 예외 맞는 처리 수행
} catch(Exception 1) {
// ... 예외 처리
} catch(Exception 2) {
// ... 예외 처리
}
하지만 만일 try 문 안에서 어떤 예외가 발생하여 즉시 중단되고, catch 문이 수행되더라도 반드시 완료되어야 할 부분이 있다면 어떻게 해야할까 ?
이런 경우 ‘try-catch-finally’ 구문을 사용한다.
public void connectServer() {
try {
// ... 서버 접속 요청
} catch (Exception e) {
// ... 접속 실패 로그 및 대기
} finally {
// ... 리소스 반납 및 정리
}
}
finally 문 안의 내용은 try 문 안에서의 예외 발생 여부와 상관없이 무조건 실행된다. 따라서 위 코드를 예로 들면 클라이언트가 서버에게 접속을 요청하고 응답을 기다리는 동안 어떤 예외가 발생하여 catch 문이 실행되면서 접속 실패 로그를 출력하고 잠시 대기하더라도 그와 관계없이 finally 문의 리소스 반납 및 정리 작업이 수행된다.
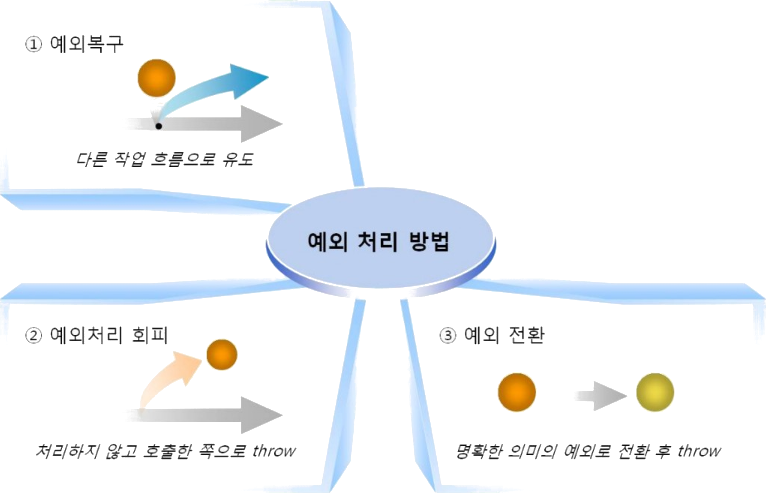
기본적으로 예외가 발생했을 때, 예외를 처리하는 방법은 3 가지로 구분된다.
- 예외 복구
- 예외 처리 회피
- 예외 전환
예외 복구
예외 복구의 핵심은 예외가 발생하더라도 애플리케이션의 정상적인 흐름을 방해하지 않는다는 것이다. try 문 안에서 예외 발생시, 해당 예외에 맞는 catch 문을 수행하지만 실패한 작업의 복구를 시도하거나 다른 작업 흐름으로 유도한다.
아래 예시 코드를 통해 살펴보자.
public void connectServer2(int countRetry) {
while(countRetry -- > 0) {
try {
// ... 서버 접속 요청
return; // 성공시 리턴
} catch (Exception e) {
// ... 접속 실패 로그 및 대기
} finally {
// ... 리소스 반납 및 정리
}
}
System.out.println("Connection fail!");
}
위 코드는 재시도를 통해 예외를 복구하는 모습을 볼 수 있다. 만일 클라이언트의 서버 접속이 실패하여 예외가 발생하더라도 최대 재시도 횟수만큼 서버 접속 요청을 계속 시도한다. 이처럼 재시도를 통해 정상적인 애플리케이션 흐름을 진행하도록 하거나 다른 흐름으로 유도하게 된다면 비록 예외가 발생했더라도 정상적으로 작업을 종료할 수 있다.
예외 처리 회피
이 방법은 말그대로 예외 처리를 회피하는 것이며 ‘예외를 뒤로 미룬다’ 라고도 표현한다.
public void run() throws SQLException {
// ...
}
위와 같이 ‘throws’ 라는 키워드를 사용한다. 이것은 예외가 발생했을 때, 메서드를 호출한 Caller 에게 예외를 전달하는 것 외에 다른 처리를 하지 않는다. 단, 이렇게 구현하는 경우는 해당 예외를 Caller 쪽에서 받아 반드시 처리하는 것을 보장하거나 더 효율적인 방법이 될 수 있을 때 사용한다. 예외를 잡고 아무런 처리도 하지 않는 것은 정말 위험한 행위이다.
public void caller1() throws SQLException {
run();
}
public void caller2() {
try {
run();
} catch (SQLException e) {
e.printStackTrace();
}
}
위 코드를 보면 run() 을 호출한 두 메서드는 각각 다른 방법으로 예외를 처리한다. caller1() 은 run() 에서 발생한 예외를 받아 throws 키워드를 통해 다른 Caller 에게 다시 전달하고, caller2() 는 try-catch 문을 통해 직접 예외를 처리한다. 이처럼 예외 처리 회피 방법은 예외를 Caller 에게 전달만 함으로써 자신의 처리를 회피한다.
public void connectServer3(int countRetry) throws RetryFailedException {
while(countRetry -- > 0) {
try {
// ... 서버 접속 요청
return; // 성공시 리턴
} catch (Exception e) {
// ... 접속 실패 로그 및 대기
} finally {
// ... 리소스 반납 및 정리
}
}
// System.out.println("Connection fail!");
throw new RetryFailedException(); // 최대 재시도 횟수를 초과하면 직접 예외 발생
}
이전의 코드를 개선한 모습이다. 이전의 방법에서는 최대 재시도 횟수를 초과한 경우 단순히 콘솔 출력문을 사용했기 때문에 Caller 입장에서는 재시도 횟수 초과 여부를 알 수 없었다. 하지만 이제 직접 예외를 발생시키고 전달함으로써 Caller 입장에서 최대 재시도 횟수를 초과한 사실을 명확하게 알 수 있다.
예외 전환
} catch (SQLException e) {
throw new DuplicateUserException(e);
}
이처럼 예외 전환은 예외를 잡아서 다른 특정 예외로 전달하는 것이다. 정확히 말하자면 발생한 예외에 대해 명확한 의미의 예외로 구체화 및 전환시켜 Caller 에게 전달하는 것이다. 따라서 호출한 Caller 쪽에서 해당 예외를 받아 처리할 때, 좀 더 명확하게 처리할 수 있게 된다.
} catch (SQLException e) {
throw new RuntimeException(e);
}
또는 Checked Exception (특히 복구 불가능한 예외) 이 발생했을 때, 이를 RuntimeException 으로 묶어 전달함으로서 다른 계층에서 일일이 예외를 선언할 필요가 없도록 할 수도 있다.
하위 계층에서 던져진 Checked Exception 은 이 예외를 반드시 잡아내거나 다시 throw 해야된다는 것을 강제하는데, 상위 계층에서 이런 예외들을 효율적으로 처리할 수 없는 경우에는 원하지 않는 짐이 되어버린다.
이것으로 이번 포스트를 마치며, 이번 포스트를 작성하면서 예외 처리를 이해하고 이를 효율적으로 사용하는 것은 정말 중요하지만 초급 개발자에겐 쉽게 지나칠 수 있는 부분이라고 느꼈습니다. 따라서 어떤 처리를 해야 하는지 모르더라도 무작정 예외를 잡고 무시하거나, 단순히 던져버리는 행위를 할 때는 더욱 신중해야 합니다.
결과적으로 개발자로써 사용자가 원하는 동작을 구현하는 것 뿐만아니라 안전하고 유연한 프로그래밍을 위해 예외 처리 능력을 키우는 것은 매우 중요한 숙제라고 생각합니다.
감사합니다.