[JAVA] Thread 3
Seongje kim, 16 January 2020
지난 포스트에서 이어서 Java의 스레드에 대한 마지막 내용입니다. 아래는 스레드 1, 2 부 포스트입니다.
(Java) Thread 1
(Java) Thread 2
스레드 동기화(Synchronization)
앞서 스레드 2 부에서 설명한 ‘스레드 안정성(Thread-Safe)’ 이라는 개념을 기억할 것이다. 스레드 안정성의 키워드는 ‘정확성’ 이다. 구체적으로 멀티 스레드로 설계된 프로그램의 정확한 동작을 보장하는 것이다.
멀티 스레드 내부에서 발생할 수 있는 예측 불가한 결과는 공유 자원을 사용하는 스레드 간의 ‘경쟁 상태(Race Condition)’ 로부터 발생한다. 즉, 스레드 안정성을 위협하는 요소이다.
결과적으로 경쟁 상태를 유발할 수 있는 공유 자원에 대한 관리가 필요하며 이를 해결하기 위해 Java에서는 기본적으로 synchronized 라는 키워드를 통해 동기화(Synchronization)를 제공한다.
이제 아래 경쟁 상태의 예시와 코드들을 보며 Java의 스레드 동기화에 대해 알아보자.
먼저 ‘단일 연산’ 이란 중단되지 않는 연산을 말한다. 또한 운영체제 개념에서는 원자성(Atomic)을 가지는 연산으로 표현된다. 이를 스레드 관점으로 표현한다면 작업 A 를 실행 중인 스레드 입장에서 작업 B 를 실행 중인 다른 스레드를 볼 때 작업 B 가 모두 수행됐거나 전혀 수행되지 않은 상태로 파악된다면 작업 B 는 단일 연산이라고 말한다. 즉, 어떤 작업이 단일 연산을 보장한다면 해당 작업을 수행하는 동안 동시에 다른 스레드의 접근이 불가함을 뜻한다.
경쟁 상태 예시 (1) : 스레드의 타이밍에 따라 결과가 달라지는 경우
public class UnsafeSequence {
private int value;
public int getNext() {
return value++;
}
public int getPrev() {
return value--;
}
}
getNext(), getPrev() 메서드가 각각 value 값을 증가, 감소시켜 반환하는 것은 사실 3 개의 명령으로 이루어진다.
- value 값 읽기
- 값 연산
- value 에 저장
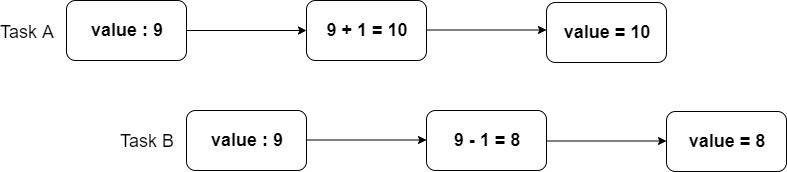
하지만 위 그림의 예시와 같이 value 가 공유 변수일 경우 문제가 발생할 수 있다. 각 스레드의 작업인 Task A, Task B 의 수행을 통해 의도한 동작 결과는 value 값이 9 가 되어야 하지만 스레드의 접근 시점에 따라 예상과는 다른 결과를 유발할 수 있다. 따라서 스레드의 타이밍에 따라 예측할 수 없는 결과를 발생시킬 위험을 해결하기 위해 각 스레드가 변수에 접근하는 시점을 적절하게 조율해야 한다. 즉, 공유 자원을 사용하는 임계 영역(Critical Section)은 상호 배타적으로 수행되어야 한다.
public class SafeSequence {
@GuardedBy("this") // 해당 필드 또는 메서드를 사용하려면 반드시 지정된 락(Lock)을 확보한 상태에서 사용해야 함을 의미
private int value;
public synchronized int getNext() {
return value++;
}
public synchronized int getPrev() {
return value--;
}
}
위와 같이 코드를 작성하면 멀티 스레드 환경에서 데이터 공유 문제를 해결할 수 있다. Java에서 제공하는 synchronized 키워드는 해당 블록에 대해 단일 연산의 특성을 보장하기 위한 ‘락(Lock)’ 을 제공한다. synchronized는 락으로 사용될 객체의 참조 값과 해당 락으로 보호하려는 코드 블록으로 구성된다.
synchronized (lock) { // lock은 보호할 객체의 참조 값
/*
단일 연산으로 만드려는 코드 블록
*/
}
메서드 선언부에 지정된 synchronized 키워드는 해당 메서드 내부의 전체 코드를 포함하며 이 메서드를 포함한 클래스의 인스턴스를 락으로 사용함을 의미
Java에서 락은 상호 배제(Mutex)를 기반으로 동작하기 때문에 순간에 한 스레드만이 특정 락을 소유할 수 있다. 다시 말해 하나의 스레드만이 특정 lock 으로 보호된 synchronized 블록으로 들어갈 수 있다. 결과적으로 synchronized 키워드를 통한 동기화를 적용하여 공유 자원 접근에 대한 관리와 정확한 동작 결과를 보장할 수 있다.
경쟁 상태 예시 (2) : 상태가 없는 경우
public class StatelessFactorizer implements Servlet {
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = factor(i);
encodeIntoResponse(resp, factors);
}
}
위의 서블릿(Servlet)은 공유하고 있는 상태가 존재하지 않는다. 메서드 안의 일시적인 상태는 해당 스레드의 스택(Stack)에 저장되기 때문에 다른 스레드가 접근할 수 없다. 그러므로 위 메서드를 실행하는 스레드는 서로 상태를 공유하지 않으며, 상태가 없는 객체는 항상 스레드 안정성을 보장한다.
경쟁 상태 예시 (3) : 상태가 1개인 경우 (Atomic 클래스를 통한 해결)
public class CountingFactorizer implements Servlet {
private final AtomicLong count = new AtomicLong(0);
public long getCount() { return count.get(0); }
public void service (ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = factor(i);
count.incrementAndGet();
encodeIntoResponse(resp, factors);
}
}
java.util.concurrent.atomic 패키지는 숫자나 객체 참조 값에 대해 상태를 단일 연산으로 변경할 수 있는 클래스들을 제공한다. 위처럼 AtomicLong 타입으로 선언된 count 변수는 모두 단일 연산으로 처리되기 때문에 스레드 안전하다.
그렇다면 상태가 여러 개인 경우에도 Atomic 클래스를 이용해 해결할 수 있을까?
아니다. 상태가 여러 개라면 일관성을 유지하기 위해 관련 변수들을 하나의 단일 연산으로 갱신해야 한다.
이때 필요한 것이 바로 ‘synchronized’ 이다.
public class UnsafeCachingFactorizer implements Servlet {
private final AtomicReference<BigInteger> lastNumber = new AtomicReference<BigInteger>();
private final AtomicReference<BigInteger> lastFactors = new AtomicReference<BigInteger>();
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
if (i.equals(lastNumber.get()) encodeIntoResponse(resp, lastFactors.get());
else {
BigInteger[] factors = factor(i);
lastNumber.set(i);
lastFactors.set(factors);
encodeIntoResponse(resp, factors);
}
}
}
위의 코드는 스레드 안전하지 않다.
lastNumber.set(i);
lastFactors.set(factors);
이 값을 갱신하는 연산들이 전부 완료되기 전에 다른 스레드가 메서드를 실행시키면 결과 값이 정확하게 나오지 않을 가능성이 있다. 그러므로 상태를 일관성 있게 유지하려면 synchronized 키워드를 추가하여 위 연산들을 하나의 단일 연산으로 만들어야 한다.
public synchronized void service(ServletRequest req, ServletResponse resp) {...};
이 방법은 메서드 선언부에 synchronized 키워드를 추가하여 해결한 모습이다. 하지만 보호해야 할 코드 이외의 부분까지 전부 동기화되었기 때문에 성능이 떨어질 수 있는 문제가 있다. 또한 동기화 영역이 커지면 스케줄러와 우선순위에 따라 해당 스레드의 재진입 가능성이 증가하면서 다른 스레드의 활동성이 떨어질 수 있다.
재진입성 : 특정 스레드가 자기가 이미 획득한 락을 다시 확보할 수 있다. (스레드 단위로 락을 얻는다는 것을 의미)
synchronized (this) {
lastNumber.set(i);
lastFactors.set(factors);
}
위 코드는 보호해야 할 코드 블록에만 synchronized 키워드를 추가한 모습이다. 이와 같이 동기화할 경우 스레드 안정성을 보장하면서 메서드 전체를 동기화했을 때보다 성능을 개선할 수 있다.
정리
멀티 스레드 프로그램의 스레드 안정성을 보장하기 위해서 스레드 동기화는 필수적이다. 하지만 synchronized 키워드를 남용할 경우 오히려 프로그램 성능이 저하될 위험이 있다.
스레드 동기화시 synchronized 블록의 범위를 크게 설정한다면 코드가 단순해지고, 확실하게 스레드 안전성을 보장받는 장점을 얻을 수 있지만 성능이 느려질 수 있다.
따라서 스레드 안전성을 먼저 확보한 다음에 성능이 너무 느려질 수 있는 부분은 락을 잡지 않는 것을 고려해보아야 한다. 예를 들어 복잡하고 오래 걸리는 계산 작업, 네트워크(Network) 작업, 사용자 입출력(I/O) 작업 등의 빠르게 처리가 안될 수도 있는 부분은 동기화 영역에서 제외한다.
스레드 스케줄링(Scheduling)
JVM 의 스케줄링 규칙은 철저하게 ‘우선순위(Priority)’ 에 기반한다. 가장 높은 우선순위를 갖는 스레드가 먼저 스케줄링된다.
만일 두 스레드가 동일한 우선순위를 가지고 있다면 ‘라운드 로빈(Round Robin)’ 방법이 적용된다.
Java에서는 이러한 우선순위 속성을 이용해서 스레드가 수행하는 작업의 중요도에 따라 우선순위를 서로 다르게 지정하여 특정 스레드가 더 많은 작업 시간을 갖도록 할 수 있다.
public static final int MAX_PRI = 10 // 최대 우선순위
public static final int MIN_PRI = 1 // 최소 우선순위
public static final int AVG_PRI = 5 // 보통 우선순위
// 제공 메서드
void setPriority(int newPriority);
int getPriority();
스레드의 우선순위는 1 ~ 10 의 정숫값 을 지정할 수 있으며 숫자가 높을수록 우선순위가 높다는 것을 뜻한다. 기본적으로 설정된 메인 스레드의 우선순위는 5이다.
또한 스레드의 우선순위는 직접 설정하지 않는다면 해당 스레드를 생성한 스레드(같은 ‘스레드 그룹’)로부터 상속받는다. 예를 들어 main() 에서 생성한 스레드의 우선순위는 자동적으로 5가 되는 것이다.
스레드 그룹(Group)
우선순위의 부여는 스레드 그룹 단위로도 가능하다.
스레드 그룹은 서로 관련된 스레드를 그룹으로 다루기 위한 것이며 그룹 단위로 적용되는 특정 메서드들을 제공한다. 또한 스레드 자신이 속한 스레드 그룹이나 하위 스레드 그룹은 변경할 수 있지만 다른 스레드 그룹의 스레드는 변경하지 못한다. 이는 보완성과 관련이 있다.
스레드를 스레드 그룹에 포함시키려면 Thread 의 생성자를 이용해야 한다. 단, 모든 스레드는 반드시 스레드 그룹에 포함되어야 하기 때문에 스레드 그룹을 지정하는 생성자를 사용하지 않은 스레드는 기본적으로 자신을 생성한 스레드와 같은 스레드 그룹에 속하게 된다.
스레드 실행 제어
앞서 설명했듯이 우선순위를 주어 스레드 간의 스케줄링이 가능하지만 이 방법은 제한적인 면이 있다. 따라서 Java에서는 추가적으로 스케줄링과 관련된 메서드들을 제공하며 이를 이용하여 더욱 구체적인 스레드 스케줄링 설계가 가능하다.
스레드 실행 제어 메서드를 수행하게 되면 해당 스레드는 스레드 생명 주기 중 한 특정 상태가 된다. 스레드들의 상태 변화와 이들의 관계를 파악하여 실행 제어 메서드들을 잘 활용한다면 프로그램의 응답성과 효율성을 높일 수 있는 장점을 가진다. 단, ‘교착상태(Dead Lock)’ 와 같은 문제가 발생하지 않도록 동기화가 우선시 되어야 하며 잘못 사용하면 오히려 성능이 저하될 가능성이 있기 때문에 주의 깊게 사용해야 한다.
결과적으로 우선순위와 함께 다양한 스레드 실행 제어 메서드들과 스레드 생명 주기(상태)를 잘 파악하여 적절한 스레드 스케줄링 설계를 한다면 이에 따라 멀티 스레드 프로그램의 성능 향상을 꾀할 수 있을 것이다.
각 스레드 실행 제어 메서드는 아래 Java 참조 문서를 통해 확인할 수 있다.
Thread (Java Platform SE 8) - Oracle Help Center
메모리 가시성(Visibility)과 메모리 장벽(Barrier)
마지막으로는 Java 메모리 모델과 병렬 프로그래밍과 관련하여 다소 심화된 내용을 다룰 것이다.
하드웨어 메모리 아키텍처 (Hardware Memory Architecture)
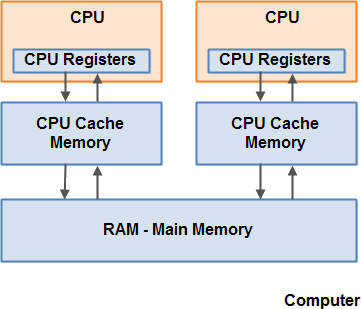
근래의 컴퓨터는 기본적으로 멀티 이상의 코어를 가진다. 위 그림의 메모리 구조를 보면 각 CPU 는 자신의 레지스터 및 캐시 메모리를 가지며 모든 CPU 가 공유하는 메인 메모리가 존재한다. 이들이 명령을 수행하는 속도는 CPU 가 접근하는 속도와 비례한다. 레지스터, 캐시 메모리, 메인 메모리의 순으로 CPU 가 접근하는 속도가 느리다.
보통 CPU 가 메인 메모리로의 접근을 필요로 할 때 메인 메모리의 일부를 캐시로 읽어 드린다. 그리고 다시 이 캐시의 일부를 내부 레지스터로 읽어 드리고 명령을 수행한다.
이후 데이터를 메인 메모리에 저장하기 위해 이 과정을 역순으로 밟는다. 작업 결과를 레지스터에서 캐시로 보내고 적절한 시점에 캐시에서 메인 메모리로 보낸다. 캐시가 데이터를 메인 메모리로 보내는 적절한 시점이란 CPU 가 캐시에 다른 데이터를 저장해야 할 때이다. 이는 ‘캐시 라인(Cache Lines)’ 이라고 불리는 작은 메모리 블록에 데이터를 갱신하는 행위이다.
또한 각 CPU 는 한개의 스레드를 동작시킬 수 있다.
따라서 멀티 스레드 환경의 프로그램 안에서 CPU 당 하나의 스레드(여러 스레드)가 동시에 작동 될 수 있음을 알 수 있다.
JVM
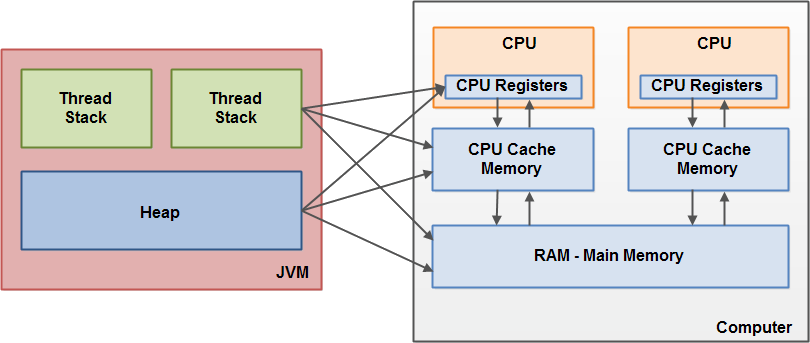
JVM 과 다르게 하드웨어는 스레드의 스택과 힙을 구분하지 않으며 이들은 모두 메인 메모리에 위치한다. 그리고 위 그림과 같이 경우에 따라 스레드 스택과 힙의 일부분은 종종 레지스터와 캐시에도 나타날 수 있다. 결과적으로 객체와 변수들은 시점에 따라 다양한 메모리 영역에 존재할 수 있는 것이다.
재배치 (Reorder)
int a = 1;
int b = 2;
a++;
b++;
위 작성된 코드를 보고 우리는 순서대로 변수 a, b 의 선언과 함께 값을 할당하고 a, b 의 값을 증가시키는 명령이 수행될 것을 예상한다. 하지만 CPU 가 실제로 명령을 수행하기 전에 JVM 은 컴파일러의 성능 최적화를 위해 프로그램의 의미가 달라지지 않는 한에서 명령의 순서을 아래와 같이 재조정 시킨다.
int a = 1;
a++;
int b = 2;
b++;
이처럼 프로그램이 최대한 빠르게 실행될 수 있도록 하는 효율적인 CPU 레스지터 및 캐시 활용을 위해 컴파일러가 명령을 최적화하는 것을 ‘재배치’ 라고 한다.
결과적으로 컴파일러의 이러한 특징 때문에 동기화 되지 않은 상황에서 메모리상의 변수를 대상으로 작성한 코드가 반드시 ‘그 순서대로 동작한다’ 라는 점을 보장하지 않는다.
메모리 가시성
- 다중 코어와 CPU 당 레지스터 및 캐시의 존재
- 스레드 동시성(Concurrency)
- 하드웨어와 JVM 의 메모리 구조 차이
- 컴파일러 최적화
위 4가지 요소들은 공유 자원을 사용하는 멀티 스레드 환경에서 문제를 유발시킬 수 있다.
먼저 주요 이슈는 ‘JVM 이 메인 메모리로부터 데이터를 캐시 또는 레지스터로 읽어(read) 들이거나 또는 반대로 메인 메모리에 데이터를 쓰는(write) 정확한 시점을 보장하지 않는다’ 는 점이다. 더 나아가 이 점은 각 CPU 마다 해당되며 이들은 동시에 수행될 수 있다는 것을 기억하자.
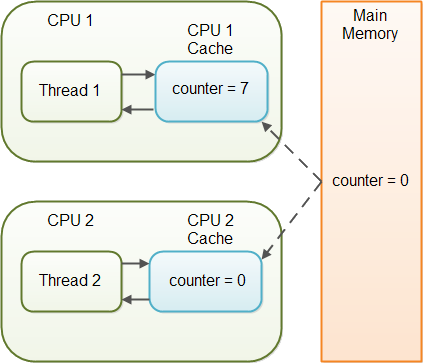
위 그림은 동시에 수행 가능한 각 CPU 의 스레드마다 자신이 원하는 시점에 메인 메모리로부터 데이터를 읽거나 쓰는 것을 보장해 주지 않기 때문에 발생하는 문제를 보여준다.
이처럼 둘 이상의 스레드가 공유하는 변수 또는 객체에 아무런 작업을 하지 않았다면 CPU1 캐시에 변경된 값이 언제 메인 메모리에 쓰이는지 보장하지 않기 때문에 CPU2 캐시가 메인 메모리로부터 읽는 값이 변경된 값인지 아닌지 확신할 수 없다. 둘 이상의 스레드가 같은 변수 또는 객체에 대해 다른 값을 가질 수 있는 것이다.
결과적으로 일부 스레드에서 공유 변수의 값을 변경하더라도 일정 시점에 메인 메모리에 반영하는 것을 보장하지 않기 때문에 다른 스레드에서 최신 값을 받아오지 못할 수 있다. 즉, 다른 스레드가 해당 변수의 상태 변경 사실을 볼 수 없는 문제(가시성 문제)가 발생한다.
정리하자면 ‘메모리 가시성’ 은 다중 코어에서의 메모리 구조, 캐시와 레지스터의 존재, 스레드 동시성, 컴파일러 성능 최적화로 인하여 어떤 스레드의 일부 상태 업데이트(쓰기) 작업에 대해 자신 외에 다른 스레드가 상태의 변경을 볼수 없는 상황이 발생하는지의 여부를 말한다.
메모리 장벽
결국 한 코어(CPU)에서의 값 변경 상태를 여러 코어(CPU)가 공유하는 메인 메모리로 반영하는 작업을 적절히 수행해야 캐시와 메인 메모리 간 값의 불일치를 해결하고 메모리 가시성을 보장할 수 있다. 또한 CPU의 레지스터 또는 캐시의 값을 메인 메모리로 반영하는 것은 상대적으로 느리지만 꼭 필요한 작업이다.
따라서 적절히 필요한 시점에만 메인 메모리로 반영하도록 하는 것이 필요하다. 이 개념이 바로 ‘메모리 장벽’ 이다.
메모리 장벽을 만나면 다른 CPU 에서 최신 값을 읽어올 수 있도록 그전에 해당 CPU 의 레지스터나 캐시에 변경되었던 값을 전부 메인 메모리에 반영한다. 이 메모리 장벽은 값을 변경하는 CPU 뿐만 아니라 값을 읽는 CPU 에서도 잘 사용해야 한다. 변경 값이 적절히 메인 메모리에 반영되더라도 값을 읽으려는 CPU 가 자신의 레지스터나 캐시에서 읽는다면 소용이 없기 때문이다.
컴파일러는 메모리 장벽을 넘어서까지 재배치를 하지 않기 때문에 컴파일러 최적화로 인한 메모리 가시성 문제가 발생하지 않는다.
이제 메모리 장벽을 사용하기 위해서 컴파일러가 메모리 장벽을 설치하도록 명령해야 한다.
Java에서는 이를 위해 ‘Lock’ 또는 ‘volatile’ 을 사용한다.
- 일반적으로 동기화를 이용한 Lock 을 사용하는 곳에는 메모리 장벽이 설치된다.
synchronized 키워드 또는 Atomic 패키지를 사용한 동기화 시 자동으로 메모리 장벽이 설치되고 메모리 가시성을 보장할 수 있다. Lock 을 소유하고 있는 스레드가 특정 메모리에 Lock 사용을 표시하고, 다른 스레드는 그 값을 보고 자신이 Lock 을 소유할 수 없는 상태라는 것을 판단해야 하기 때문에 Lock 을 메모리를 쓰고 읽는 과정에 메모리 장벽이 필수적이기 때문이다.
- 변수에 volatile 키워드를 선언한다.
volatile 으로 선언된 변수에 대한 쓰기 작업은 전부 메인 메모리에 즉시 쓰이고, 읽기 작업은 메인 메모리로부터 직접적으로 읽어지기 때문에 메모리 가시성을 보장해 줄 수 있다.
public class SharedObject {
public volatile long counter = 0;
}
이처럼 volatile 으로 선언된 변수는 여러 스레드에서 항상 최신 값으로 가지고 갈 수 있도록 한다. 또한 한 스레드가 volatile 변수를 수정할 때 단지 volatile 변수만 메인 메모리에 저장하는 것이 아니라 volatile 변수를 수정하기 전에 수정한 모든 변수들이 함께 메인 메모리에 저장(Flushed)된다.
대표적인 예로 Java에서 long 과 double과 같은 64 비트 연산은 32 비트씩 나누어 두번의 연산을 하기 때문에 여러 스레드가 간섭할 문제가 있지만 volatile 키워드를 선언한다면 long 과 double 연산에서 원자성을 보장받을 수 있다.
그러나 volatile 키워드가 메모리 가시성을 보장하는 것은 맞지만 이것만으로 스레드 간 경쟁 상태를 해결하진 못한다. 단지 volatile 키워드는 읽기/쓰기 명령을 메인 메모리로부터 수행하여 최신 값이란 것만 보장할 뿐, 공유 변수에 접근하는 다른 스레드들을 블록 시키지 않기 때문이다. 즉, 연산의 단일성 또는 스레드 안정성을 보장하지 못한다.
만일 한 변수를 두고 오직 한 스레드만 이 변수에 읽기/쓰기 작업을 하고, 다른 스레드들은 읽기 작업만 하는 상황에서라면 이 때는 volatile 선언이 유효할 수 있다.
정리하자면 메인 메모리로부터 데이터를 읽고 쓰는 작업은 CPU 캐시를 이용하는 것 보다 많은 비용이 요구된다. 또한 volatile 선언은 JVM 성능 향상의 방법인 컴파일러 최적화를 막기도 한다. 그러므로 volatile 키워드는 변수의 메모리 가시성 보장이 반드시 필요한 경우에만 사용되어야 하며 volatile 키워드 대신 Atomic 패키지 클래스들을 먼저 고려해보는 것이 좋다고 생각한다.
정리
결론적으로 다중 코어를 대상으로 하는 멀티 스레드 환경의 프로그래밍에서 공유되는 메모리와 관련된 ‘메모리 가시성’ 을 파악하고 적절히 ‘메모리 장벽’ 을 사용하는 것이 필요하다.
이것으로 3 부에 걸쳐 다뤘던 Java 스레드에 대한 포스트를 마치겠습니다. 감사합니다.