[JAVA] Memory structure
Seongje kim, 20 October 2019
첫 포스트에 앞서 앞으로 대부분 Java와 Spring을 주로 다룰 예정입니다. 또한 모든 포스트의 주제와 내용은 개인적으로 공부한 것들을 정리하여 올리는 것이기 때문에 다소 미흡한 부분이 있을 수 있고, 설명은 내용을 기술하는 방식으로 진행할 예정입니다.
첫 포스트의 주제는 Java의 메모리 구조에 대한 기본적인 내용입니다.
Java의 메모리 구조 및 컴파일 과정
일반적인 프로그램 또는 프로세스는 OS(Operating System) 위의 메모리에서 동작한다. 하지만 Java 프로그램은 OS 에 독립적으로 실행된다. 그 이유는 JVM(Java Virtual Machine) 이라는 특별한 가상 머신이 OS 와 Java 프로그램 사이에 위치하고 OS 에게 메모리 사용 권한을 부여받아 Java 프로그램을 호출하여 기계어로 해석해주는 역할을 하기 때문이다.
그렇다면 이와 같은 JVM 의 장점은 무엇일까?
앞서 말했듯이 Java 프로그램은 JVM 위에서 OS 에 독립적으로 실행된다. 이는 Java 프로그램이 OS 에 종속적이지 않고 어떤 디바이스 또는 환경에서도 JVM 위에서 프로그램을 실행할 수 있다는 큰 장점이 된다. 하지만 OS 으로부터 직접 제어 받는 방식보다 속도 면에서 느릴 수밖에 없다. (이를 보완하기 위해 특별한 컴파일러를 가진다.)
아래는 JVM 의 전체 구조이다.
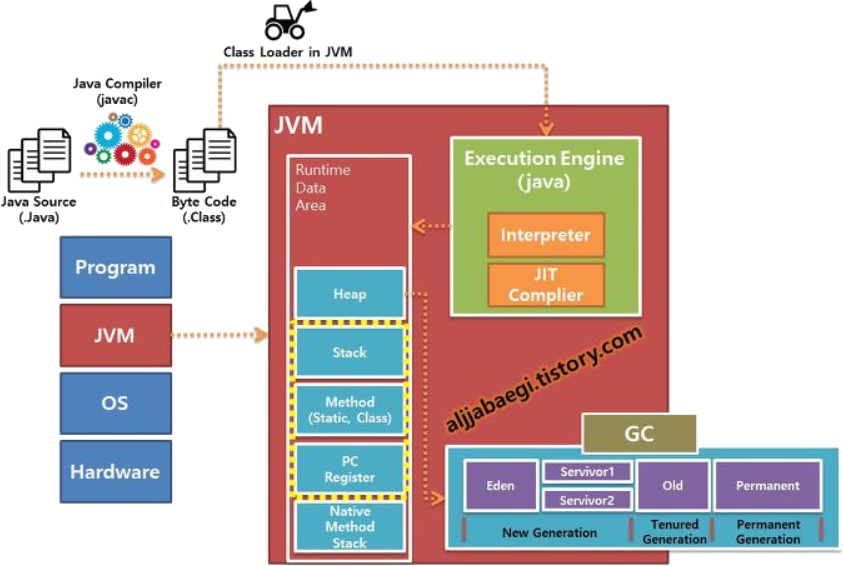
JVM 은 크게 Class Loader, Execution Engine, Runtime Data Area 으로 구성되어 있다.
차례로 하나씩 살펴보자.
- Class Loader
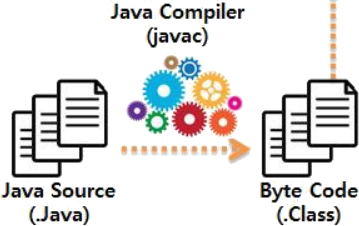
우선 기본적으로 Java 개발 툴(ex. Eclipse)에서 작성된 Java 코드는 .java 파일로 저장된다. 그 후 Java 파일의 빌드가 이루어지면 Java 컴파일러는 javac 이라는 명령어를 통해 .class 파일을 생성한다.
.class 파일은 바이트 코드(Byte Code, 반기계어)이기 때문에 OS 에서 바로 실행될 수 없다. 그래서 JVM 은 OS 가 해당 바이트 코드를 이해할 수 있도록 해석해주는 역할을 한다. 이제 런타임 시점이 되면 Class Loader 에 의해 JVM 내부에 로드된다.
- Execution Engine
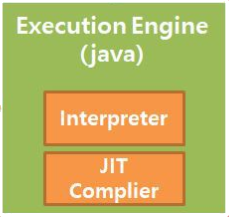
그다음 JVM 내 로드된 바이트 코드는 Execution Engine 에 의해 기계어로 해석되어 메모리 상(Runtime Data Area)에 배치된다.
Execution Engine 은 인터프리터와 JIT(Just In Time) 컴파일러로 구성되어 있다. 앞서 말한 코드가 JVM 을 통해 해석되기 때문에 OS으로부터 직접 제어 받는 방식보다 속도 면에서 느리다는 단점을 보완하기 위해 JIT 컴파일러가 존재한다. 인터프리터는 바이트 코드를 한줄씩 실행하기 때문에 속도가 느리다는 단점을 가진다. 이를 보완하기 위해 JIT 컴파일러는 바이트 코드 전체를 어셈블러와 같은 네이티브 코드로 컴파일하여 직접 실행하게 된다.
JIT 컴파일러에 의해 해석된 코드는 캐시(Cache)에 보관되기 때문에 한번 컴파일 된 후에는 빠르게 수행된다. 하지만 이를 변환하는데 인터프리터 방식보다 훨씬 오래 걸린다는 비용이 발생하게 된다. 이러한 이유로 Execution Engine 은 인터프리터 방식으로 실행하다가 적절한 시점에 JIT 컴파일러 방식을 선택한다. 예를들어 한번만 실행되는 코드는 인터프리터 방식을 사용하는 것이 유리하다.
Runtime Data Area
JVM 이 프로그램을 실행하기 위해 OS 로부터 할당받은 실제 메모리 공간으로 크게 5가지로 구분된다.

1. Method Area
JVM 시작 시 생성되고 모든 스레드(Thread)가 공유하는 영역이다. JVM 구동 중 사용될 클래스 파일들을 로드하고 클래스 또는 인터페이스 관련 정보가 저장된다.
클래스 및 메서드의 Meta 정보, 정적(Static) 변수, 상수 등의 정보를 저장한다. 정적 영역의 데이터는 프로그램 종료 시까지 공유되며 메모리에 남아있게 된다. 또한 Method Area 내부에는 ‘런타임 상수풀(Runtime Constant Pool)’이라는 영역이 존재한다.
런타임 상수풀(Runtime Constant Pool)
클래스/인터페이스의 필드, 메서드, 문자열 상수 등의 레퍼런스 및 상수가 저장되며 이들의 물리적인 메모리 위치를 참조할 경우에 사용된다. 문자열 상수(String Constant)의 경우 String constant pool 이라는 별도의 관리 장소가 존재하는데, 만일 상수의 중복이 생기면 기존의 상수를 사용한다.
String s1 = "hello";
String s2 = "hello";
예를 들면 String 타입의 변수 s1, s2 에 대해 new 를 이용하여 객체를 생성하지 않고 리터럴(““)으로 생성한 두 변수의 문자열 상수 값이 같다면 두 변수가 참조하고 있는 주솟값은 같다.
하지만 Java 8 을 기준으로 정적 변수, 상수 정보가 힙 영역으로 이동되어 메모리 구조의 변화가 생겼다. 이는 나중에 더 자세히 다루도록 하겠다.
2. (JVM) Stack Area
각 스레드마다 하나씩 존재하며 스레드가 시작될 때 할당된다. 만일 추가적인 스레드 생성이 없었다면 메인 스레드에 대한 한 개의 스택만 할당된다. 클래스 내의 메서드에서 사용되는 정보들이 저장되는 공간으로 메서드 호출 시 해당 메서드에 대한 프레임을 추가하고 종료되면 프레임을 제거한다. 각 프레임은 LIFO(Last In First Out) 방식으로 실행 순서에 따라 생성되고 소멸되며 메서드의 매개 변수, 로컬 변수, 리턴 값 등의 정보를 가진다.
특히 프레임 내부의 로컬 변수 스택에서는 각 블록마다 기본 타입(Primitive) 또는 참조 타입(Reference) 변수가 추가/제거된다. 로컬 변수 스택에 변수에 대한 블록이 생성되는 시점은 초기화가 될 때, 즉 최초로 변수에 값이 저장될 때이다. 이는 Java에서 변수 초기화를 해야 하는 이유를 알 수 있다.
기본 타입 변수는 스택 영역에 실제 값을 가지지만 참조 타입 변수는 실제 값이 아닌 힙 영역이나 메서드 영역의 객체들에 대한 주솟값을 가진다.
3. Heap Area
주로 긴 생명주기를 가지는 데이터들이 저장된다. 힙 영역에는 클래스들에 대한 객체 또는 배열 등의 참조 타입 변수 정보가 저장된다.
힙 영역에 생성된 객체는 JVM 스택 영역의 변수나 다른 클래스의 필드에서 참조된다. 쉽게 말해 실제 값이 저장된 힙 영역의 주솟값을 저장하는 것이다. 만일 이를 참조하는 다른 변수나 필드가 없다면 쓰레기로 취급되어 GC(Garbage Collector) 에 의해 제거된다.
4. PC Register Area
스레드마다 하나씩 생성하며 현재 실행 중인 JVM 명령의 주솟값이 저장된다.
5. Native Method Stack Area
Java 외 다른 언어의 함수 호출(예: C/C++ 의 메서드)를 위해 할당되는 영역이다.
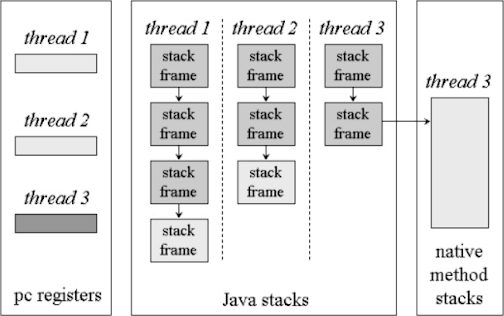
위 그림은 스레드마다 할당되는 각 영역을 보여준다.
Code
이제 직접 코드를 통해서 Stack 과 Heap 의 개념과 추가적으로 상수풀, 불변 객체(Inmmutable Object)에 대해 확인해보자.
아래는 직접 작성한 코드이다.
public static void main(String[] args) {
Integer inmmutable1 = 10;
System.out.println("Before Function Call (Value): " + inmmutable1);
System.out.println("Before Function Call (Address): " + inmmutable1.hashCode());
System.out.println("--------------In Function--------------");
IncreaseIntegerValue(inmmutable1);
System.out.println("--------------Out Function--------------");
System.out.println("After Function Call (Value): " + inmmutable1);
System.out.println("After Function Call (Address): " + inmmutable1.hashCode());
}
private static void IncreaseIntegerValue(Integer parm) {
System.out.println("Before Calculation (Parmeter Address):" + parm.hashCode());
parm += 20;
System.out.println("After Calculation (Parmeter Address):" + parm.hashCode());
}
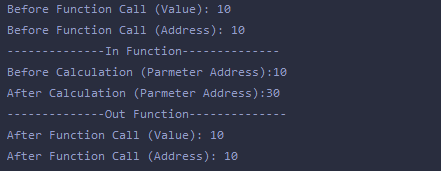
우선 코드를 보면 Integer 타입의 객체를 매개 변수로 받고 값을 20 증가시키는 메서드인 IncreaseIntegerValue 를 호출하는 간단한 코드이다. 그리고 Integer 타입의 변수 inmmutable1 에 대해 메서드를 호출하기 전, 실행 중, 실행 후의 값과 주솟값을 확인하기 위한 출력문이 포함되어 있다. 설명에 앞서 기본적으로 Java의 hashCode() 는 객체의 주솟값을 이용하여 해시 코드를 생성한다.
처음에 Integer 는 Object 타입이므로 힙 영역에 값 10 이 할당되고 그 값을 참조하는 변수 inmmutable1 가 스택 영역에 할당된다. 메서드를 호출하게 되면 매개변수 parm 에게 복사된 참조 변수(주솟값)를 넘겨주고 스택 영역에 해당 메서드의 새로운 프레임이 추가된다. 그다음 변수 parm 은 스택 영역에 할당되어 변수 inmmutable1 이 참조하는 주소를 똑같이 참조하게 된다.
이제 연산에 의해 변수 parm 의 값을 20 증가시키면 inmmutable1 의 값이 변하는가 ?
답은 당연히 변하지 않는다. 그 이유는 무엇일까?
이 질문을 답하기 위해서는 불변 객체의 개념을 알아야 한다. 불변 객체는 불변 클래스로부터 생성되며, 불변 클래스들은 참조 타입이기 때문에 그 객체들은 힙 영역에 생성된다. 불변 객체란 말 그대로 변경이 불가한 객체를 말한다. 힙 영역에 할당된 객체를 변경할 수 없다는 말과 같다. 대표적으로 불변 클래스들에는 String, Boolean, Integer, Float, Long 등 타입 관련 클래스들이 있다.
그렇지만 우리는 불변 객체인 변수 inmmutable1, parm 의 값을 변경하거나 연산할 수 있는 것을 알고 있다. 그러나 이는 변경되는 것처럼 보이더라도 실제 메모리(힙 영역)에 새로운 객체가 할당되는 것이며 기존의 값은 변경되는 않는다.
불변 객체는 변경이 불가한 특징 덕분에 멀티 스레드 환경에서 스레드 안정성(Thread-safe)을 보장한다는 장점을 가진다. 하지만 객체의 값을 변경하려 할 때마다 새로운 객체를 생성해야 하기 때문에 추가적인 비용이 발생하고, 메모리 누수와 같은 성능 저하를 발생 시킬 수 있다.
이제 위 코드 결과의 이유를 설명할 수 있을 것이다. 변수 parm 을 증가시키면 힙 영역에 새로운 값 30이 할당되고 기존 스택 영역에 할당되었던 변수 parm 은 그 새로운 값을 참조한다. 그 결과 inmmutable1 의 값과 주솟값은 그대로 유지될 수 있는 것이다.
그 후 메서드가 종료되면 해당 프레임이 제거되면서 스택에 있었던 parm 은 더 이상 힙 영역의 30 을 참조하지 않는 상태가 된다. 이것은 쓰레기(Garbage)로 분류된다.
아래는 코드 실행 결과이다.
추가적으로 상수풀의 존재도 확인해보았다.
public static void main(String[] args) {
String inmmutable2 = "hello";
String constantPool = "hello";
System.out.println("Before Change Value (Address): " + inmmutable2.hashCode());
System.out.println("Before Change Value (Constant): " + constantPool.hashCode());
inmmutable2 = "bye";
constantPool = "bye";
System.out.println("After Change Value (Address): " + inmmutable2.hashCode());
System.out.println("Before Change Value (Constant): " + constantPool.hashCode());
}
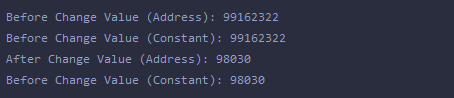
앞서 설명했듯이 String 객체는 불변 객체이므로 변수 inmmutable2 의 값을 ‘hello’ 에서 ‘bye’ 로 변경하면 기존 객체의 값이 변경되는 것이 아니라 새로운 객체가 할당된다. 때문에 당연히 변경 전과 후의 변수 inmmutable2 의 주솟값은 다르게 나올 것이다.
또한 리터럴(““)로 생성된 문자열 상수의 중복이 생기면 기존의 상수를 사용한다고 설명하였다.
그렇다면 변수 constantPool 의 주솟값을 쉽게 예상해 볼 수 있을 것이다.
아래는 코드 실행 결과이다.
Garbage Collection/Collecor(GC)
마지막으로 Java의 중요한 메모리 관리 도구인 GC 에 대해 알아볼 것이다.
우선 GC 의 개념을 알아보자.
앞서 말했듯이 JVM 의 힙 영역에는 객체들이 할당된다. 각각의 객체마다 메모리를 점유하고 있는 것이다. 하지만 그 객체가 필요하지 않음에도 불구하고 메모리를 점유하고 있다면 메모리 측면에서의 자원 손실과 심각한 성능 저하를 유발할 것이다. Java에서는 이와 같이 더 이상 필요가 없어진 객체를 쓰레기로 분류한다.
그렇다면 누군가가 이러한 쓰레기 객체들을 처리하여 메모리 손실을 방지해야 한다. 바로 Java의 GC 가 JVM 의 힙 영역에 대한 메모리 관리자로서의 역할을 수행한다. 결과적으로 GC 의 주요 업무는 효과적으로 힙 영역의 쓰레기 객체들을 찾아서 처리하는 것이다.
GC 는 Unreachable Object 를 우선적으로 메모리에서 제거하여 메모리 공간을 확보한다. Unreachable Object 란 스택 영역에서 도달할 수 없는 힙 영역의 객체이다. 이 과정은 Mark and Sweep 이라고도 한다. Mark 는 GC 가 스택 영역의 모든 변수를 스캔하면서 각각 어떤 객체를 참조하고 있는지 찾는 과정이다. 이 작업을 위해 모든 스레드는 일시 중단되는데 이를 Stop the world 라고 부른다. 그리고 Sweep 은 Marking 되어있지 않은 모든 객체들을 힙 영역에서 제거하는 과정이다.
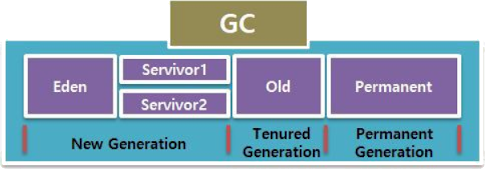
아래는 GC 의 간단한 과정을 설명하기 위해 구성 요소들을 표현한 것이다.
(Java 8 부터 Permanent Generation 영역은 Metaspace 으로 변경)

- 새로운 객체는 Eden 영역에 할당된다. Survivor Space 는 비워진 상태로 시작한다.
- Eden 영역이 가득 차면 Minor GC 가 발생한다.
- 최초에 Minor GC 가 발생하면 Reachable Object 들은 S0(Survival 0) 으로 옮겨진다. 이때, Unreachable Object 들은 Eden 영역이 비워짐과 동시에 메모리에서 제거된다.
- 다음 Minor GC 발생 시 Eden 영역은 3번과 똑같은 과정을 수행한다. 기존에 S0 에 있었던 객체들 중 살아남은 객체들은 S1(Survival 1) 으로 옮겨지며 이때, 각 객체들의 Age 값이 증가되어 옮겨진다. S1 으로 모두 옮겨지면 Eden 과 S0 영역은 비워진다.
- 다음 Minor GC 발생 시 4번 과정과 반대로 가득 차있던 S1 에서 살아남은 객체들은 S0 로 옮겨지면서 Eden과 S1 영역이 비워진다. 마찬가지로 Age 값이 증가되어 옮겨진다.
- 4,5번 과정을 반복하면서 Young Generation 에서 계속해서 살아남으며 Age 값이 증가하는 객체들은 Age 값이 특정 이상이 되면 Old Generation 으로 옮겨지는데, 이 단계를 Promotion 이라고 한다. Minor GC 가 반복되면 Promotion 도 계속 발생한다.
- Promotion 작업이 반복되면서 Old Generation 이 가득 차게 되면 Major GC 가 발생한다.
- Major GC 발생 시 Old Generation 의 모든 객체들을 검사하여 Unreachable Object 들을 한꺼번에 제거한다. 이때, GC 를 실행하는 스레드를 제외한 모든 스레드는 일시적으로 작업을 멈추게 되고 비교적으로 Minor GC 보다 시간이 오래걸리게 된다.
이번 포스트에서는 GC 의 간단한 과정만을 설명하고 이후 다른 포스트에서 GC 의 주제로 구체적인 개념과 과정을 다시 다루도록 하겠습니다.
이것으로 이번 포스트를 마무리하겠습니다. 감사합니다.